
Stable Diffusion is a text-based image generation machine learning model like DALL-E released by stability.ai (live example here). Stability.ai has not just open-sourced its source code for academic purposes, but also released the model weights to create customized applications. The AI model and its variants generate images based on a prompt and/or an input image. Unlike other text-to-image models such as DALL-E and Midjourney which were accessible only via cloud services, stable diffusion code and model weights that have been released publicly can run on most consumer-grade hardware equipped with a modest GPU.
AI models such as Generative Adversarial Networks (GAN) have been the standard way for generating images from scratch in the past. GAN learns to generate new data with the same statistics as the input training set using reinforcement learning (learn more). However, training GANs becomes complicated when it is attempted to train the generator as well as the discriminator extremely well. A very well-trained generator model leads to a worse discriminator model as the fundamental motivation of the two networks are opposite in nature. As mentioned in this article, other common and related issues with GANs are as follows :-
Working of Stable Diffusion
Stable Diffusion can produce high-quality images using the concept of Super Resolution. Using super-resolution, a deep learning model is trained, which is used to denoise an input image and generate a high-resolution image as an output.
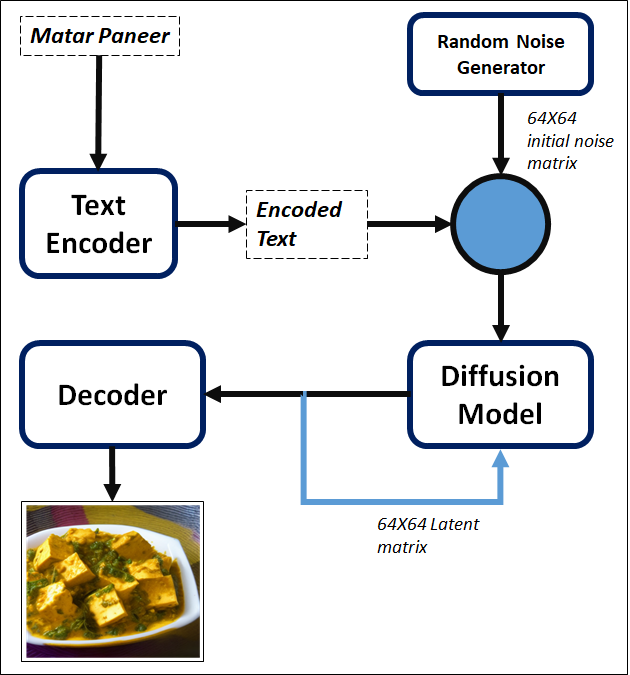
Fig 1: Overview of Stable Diffusion Model (fig source link)
As shown in Figure 1, Stable Diffusion Model comprises the following components.
We performed image-to-image stable diffusion on the images of our lab members for style transfer using this hugging-face repository. The text prompt used was van gogh. The following parameter values were used.

Fig 2: Input and output images
Blogs on Stable Diffusion
Videos on Stable Diffusion
Code on Stable Diffusion
Models on Stable diffusion on Hugging Face
References/ Research Papers on Stable Diffusion
Tags: Stable Diffusion, Turing Test, Generative Adversarial Network, Dall-E





