
Text is one of the conventional types of unstructured data. Due to this reason, most corporations do not manage textual data appropriately since it is difficult and time-consuming. The Manual analyzing and classifying process of text data can be tedious and much less accurate. Text categorization can optimize the analysis process of millions of texts including posts, documents, and emails efficiently. Organizations could efficiently classify all kinds of relevant text, such as emails, social media posts, chatbot messages, surveys, and legal records using text classifiers. As a result, we can analyze text data more quickly, automate business procedures, and optimize the decision-making process.
Although the field of text analysis as a whole is still developing, businesses including marketing, healthcare, management, academia, and government are already using techniques for analyzing and extracting information from textual data. Text classification, also known as text categorization, is the process of selecting appropriate categories from a predetermined list to apply to natural language documents. To put it another way, text categorization is the procedure used to extract general tags from unstructured text. Email spam detection is one of the most commonly used text classification techniques. Depending on the linguistic context, we can classify an email as spam or ham.
Text classification is a key component of natural language processing. Some of the usages of text classification are:-
Nevertheless, the majority of text classification tutorials available online use binary text classification, for instance, sentiment analysis of tweets with negative and positive labels. But most of the time, real-world scenarios are far more complex than that. In general, we will get more than two categories. For the above scenario, the tweets may contain not only negative or positive tweets but also neutral and irrelevant ones.
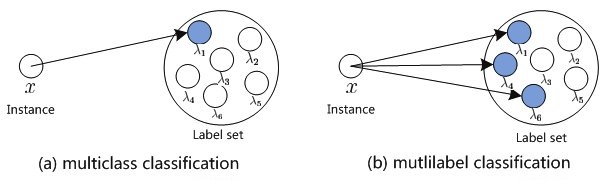
Fig 1: Supervised Learning (fig source link)
On the other hand, multi-label categorization assigns a set of target labels to every sample and the data instances are not mutually exclusive. As an example, we can take a model predicting movie genres. One movie can fall under more than one category out of a pool of labels such as romantic, comedy, horror, thriller, and drama.
Python is particularly popular due to the straightforward syntax, extensive community, and statistical libraries that are scientific computing friendly. However, depending on their needs, users also tend to favor alternative languages like R and Java. To accomplish text classification, numerous tools, APIs, and applications can also be used. Eg: Weka or the Google Cloud NLP
Some of the libraries you will require for text classification in the Python programming language are:
Support vector machines (SVM), the Naive Bayes family of algorithms, and logistic regression are some of the most widely used machine learning text classification techniques.
Deep learning can be defined as a set of algorithms and techniques inspired by the working of the human brain, called neural networks. Deep learning architectures perform at an extremely high accuracy with lower-level engineering and processing, which has significant advantages for text classification. Convolutional Neural Networks (CNN) and Recurrent Neural Networks(RNN) are the two primary deep learning architectures for classifying texts.
Transformers are also designed to analyze sequential text inputs, like recurrent neural networks (RNNs), and are beneficial in translation and text summarization. Transformers, as opposed to RNNs, process the entire input at once. Google created Bidirectional Encoder Representations from Transformers (BERT), a transformer-based machine learning approach for pre-training natural language processing (NLP). Jacob Devlin and his Google colleagues developed and released BERT in 2018. Many pre-trained transformer models can be used for text classification available on Hugging Face for a wide spectrum of domains.

Fig 1: Text classification workflow (fig source link)
However, while going through the text classification process, there are some obstacles to overcome. While preprocessing the data, cleaning the texts can be a tricky task for most people. The data may contain a considerable number of irrelevant data such as special characters, URLs, symbols, stop words, expressions, etc.). To determine the class accurately, customized NLP techniques (lemmatization, stemming, stop word removal) must be carefully carried out. Most of the multiclass text classification models may suffer from a class imbalance which will lead to giving lower performance when it comes to predicting labels with fewer data. This may also cause a higher value in the loss function. The loss function indicates the summation of the errors that your model is making. In real life working with a large dataset will require higher memory and processing power. Depending on the project you may use one or more GPUs for this purpose which will result in a higher cost.
Many enterprises are incorporating text classification in their ordinary tasks due to the consistency, scalability, and timeliness it brings in. However, there are several obstacles to overcome during conducting the classification modeling while working with real data. For example, sensitive data such as medical texts cannot be modified to increase the performance of the model. The scientific usage of text classification tasks can be further extended in overcoming critical issues in various sectors such as healthcare, government, and agriculture.
Tags: Text Classification, Multiclass classification NLP, BERT, Python, NLTK


{kind=link}